以前から、特定のWEBサイトにログインして、明細をCSVダウンロードするのを自動化していたのだが、最近”Access Denied” となって失敗するようになった。
おそらく先方のFirewallなりWAFなりのポリシーが厳しくなったのだと思う。httpのレスポンスヘッダーが、BigIPとなっていた。
selenium等のスクレイピング対策をされたのだと思う。
自分の環境は以下
- seleniumはpythonで操作
- ブラウザ環境は、dockerのstandalone-chrome
回避策としては、chromeのオプションに以下を追加する。
--disable-blink-features=AutomationControlledpythonのコードとしては、以下を追加。
options.add_argument('--disable-blink-features=AutomationControlled')
全体的なコードは以下。
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--disable-setuid-sandbox")
options.add_argument('--disable-blink-features=AutomationControlled')
selenium_url = 'http://localhost:4444/wd/hub'
driver = webdriver.Remote(
command_executor=selenium_url,
desired_capabilities=DesiredCapabilities.CHROME,
options=options,
)
driver.get("https://www.yahoo.co.jp")
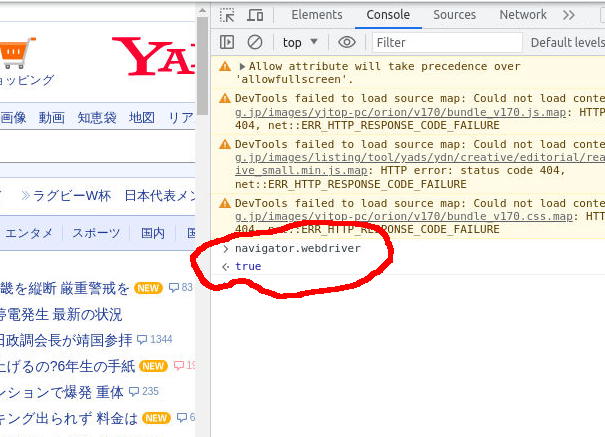
seleniumでWEBページにアクセスした場合、javascriptの navigator.webdriver が true になるらしい。
こちらを見てブロックしている模様。上のオプションは、こちらを false にしている。 実際にfalseになっているかは、chrome の Devtools で値を確認するだけ。
trueになっているとき
falseになっているとき
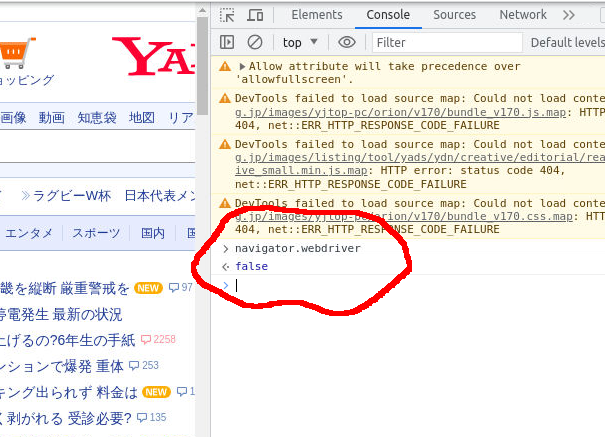
自分の環境では、このオプションでブロックを回避することができた。